altermanager告警
实现了数据看板、观测后。自然地,当服务指标发生异常现象时,我们应当立即知晓并紧急修复问题,这个时候就需要借助告警系统了。
prometheus天生支持altermanager告警,因此我们来学习下告警是如何配置,如何使用的。
拉取altermanager资源
配置文件
创建配置目录以及文件
- mkdir -p /opt/alertmanager
- cd /opt/alertmanager
- #创建配置文件
- vim alertmanager.yml
alertmanager内容如下:
- # 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
- global:
- # 告警超时时间
- resolve_timeout: 5m
- # 发送者邮箱地址
- smtp_from: '[email protected]'
- # 邮箱smtp服务器地址及端口
- smtp_smarthost: 'smtp.163.com:25'
- # 发送者邮箱账号
- smtp_auth_username: '[email protected]'
- # 发送者邮箱密码,这里填入第一步中获取的授权码
- smtp_auth_password: 'XBCODMBXMHTNOENJ'
- # 是否使用tls
- smtp_require_tls: false
- smtp_hello: '163.com'
- # 路由配置,设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- route:
- # 用于将传入警报分组在一起的标签。
- # 基于告警中包含的标签,如果满足group_by中定义标签名称,那么这些告警将会合并为一个通知发送给接收器。
- group_by: ['alertname']
- # 发送通知的初始等待时间
- group_wait: 30s
- # 在发送有关新警报的通知之前需要等待多长时间
- group_interval: 5m
- # 如果已发送通知,则在再次发送通知之前要等待多长时间,通常约3小时或更长时间
- repeat_interval: 30s
- # 接受者名称
- receiver: '163.email'
- # 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式
- receivers:
- - name: '163.email'
- email_configs:
- # 配置接受邮箱地址
- - to : '[email protected]'
- inhibit_rules:
- - source_match:
- severity: 'critical'
- target_match:
- severity: 'warning'
- equal: ['alertname', 'dev', 'instance']
启动服务
--name alertmanager \
-p 9093:9093 \
-v /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
prom/alertmanager
浏览器访问,检查服务是否已启动
若出现下图表示alertmanager成功启动
配置告警规则rules
创建告警规则路径
- mkdir -p /opt/alertmanager/rules
- cd /opt/alertmanager/rules
- #创建规则
- vi node-up.yml
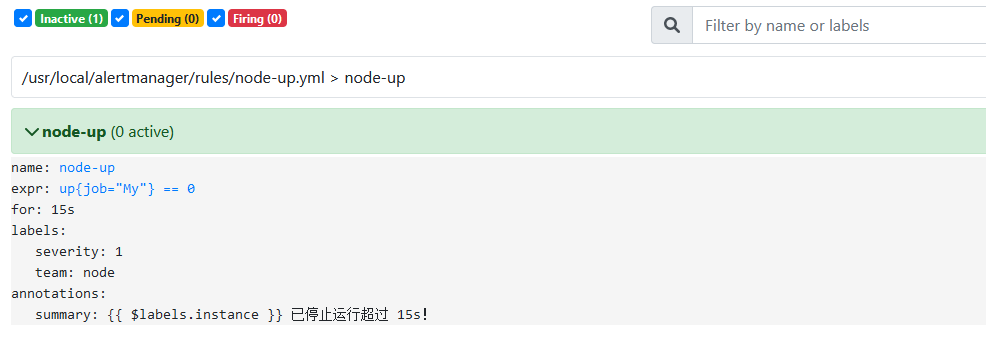
node-up.yml内容如下:
- groups:
- - name: node-up
- rules:
- - alert: node-up
- expr: up{job="node-exporter"} == 0
- for: 15s
- labels:
- severity: 1
- team: node
- annotations:
- summary: "{{ $labels.instance }} 已停止运行超过 15s!"
expr:up{job=“node-exporter”} == 0表示 服务下线 其中 node-exporter 是 prometheus.yml 文件中定义的 - job_name 修改为自己定义的名称此方式针对特定job Or 去掉大括号的内容表示所有的
for:15s 表示持续15s
annotations.summary 表示提示语
上述配置表示job(node-exporter)下线持续15s,则启动告警
配置prometheus配置文件,指定告警路由和规则
...
- # Altermanager configuration
- alerting:
- alertmanagers:
- - static_configs:
- - targets: ["192.168.11.120:9093"]
- #指定报警规则文件
- rule_files:
- - "/usr/local/alertmanager/rules/*.yml"
注意:rule_files 为容器内路径,所以启动promethus时,还需要将rules文件挂载到prometheus容器中
修改prometheus启动参数
--name prometheus \
-p 9090:9090 \
-v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /opt/alertmanager/rules/:/usr/local/alertmanager/rules/ \
prom/prometheus
这里采用Docker的方式启动,并且配置目录都不是在容器内的 , 所以直接停止源容器或者删除 , 重启启动即可
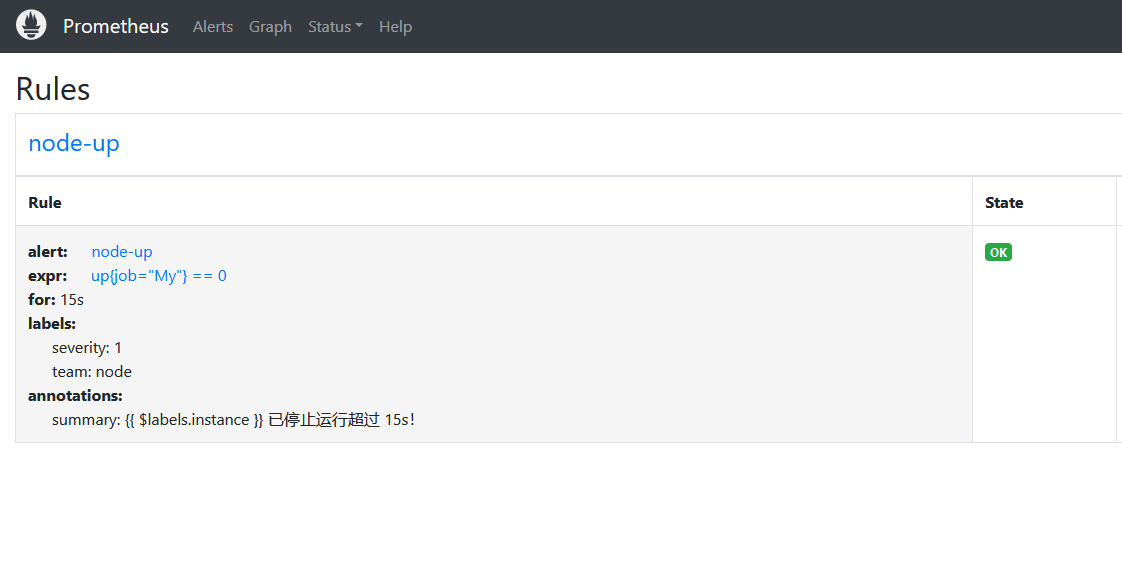
访问prometheus-rules webui界面
若出现以下界面则表示prometheus配置alertmanager成功
测试邮件告警
关闭node-exporter节点进行测试
docker stop node-exporter
在prometheus 的WEBUI界面可以看到产品告警信息
http://192.168.11.120:9090/alerts
首先是penging
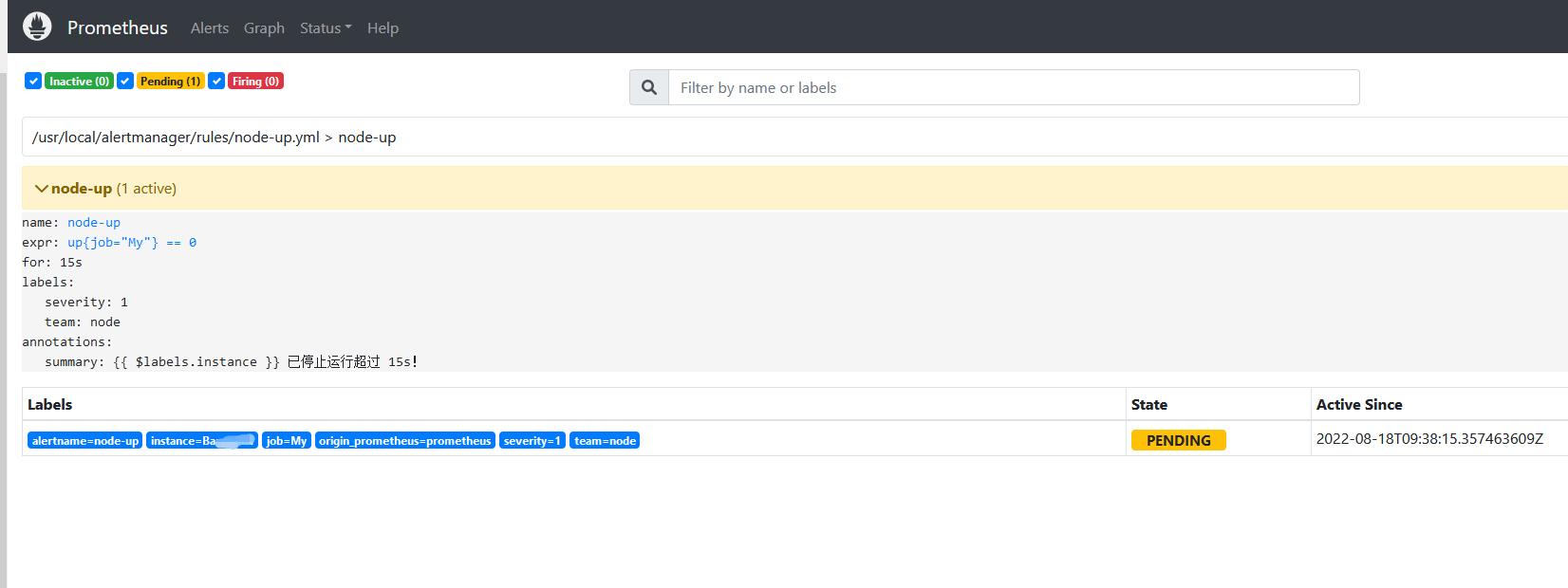
稍等一會将出现报警
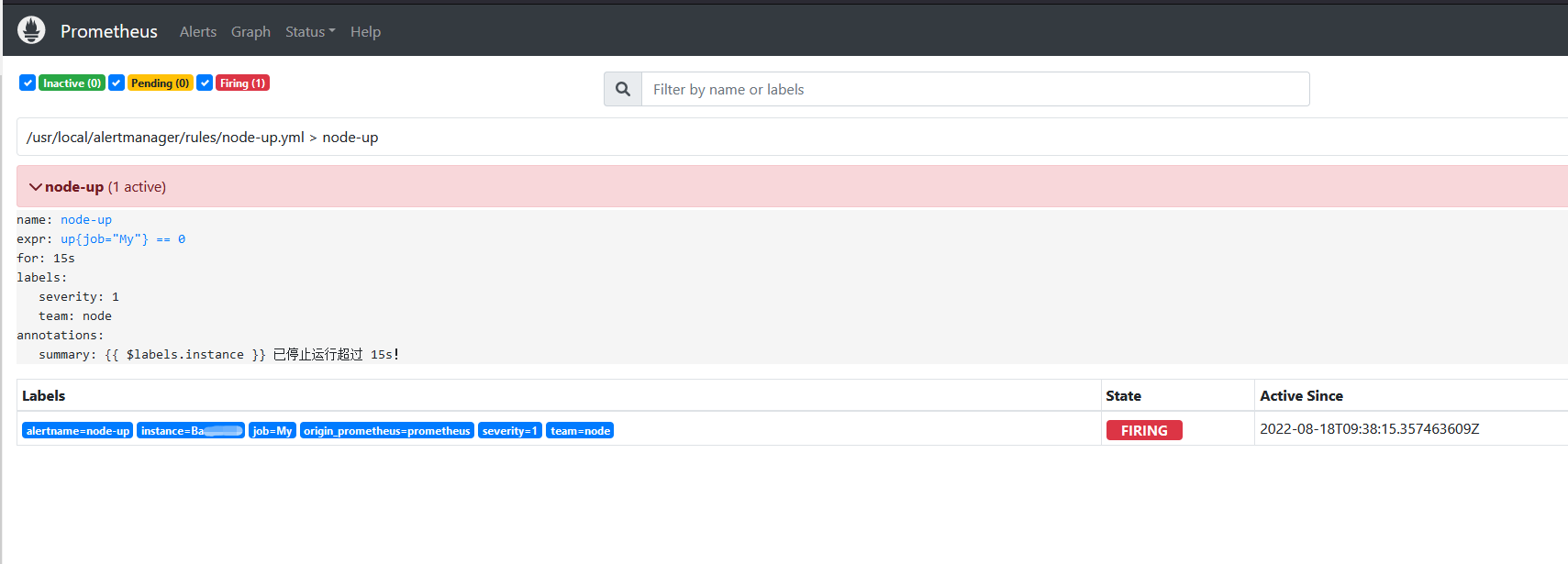
稍等刷新邮箱 查看是否有邮件 , 郵件信息如下:
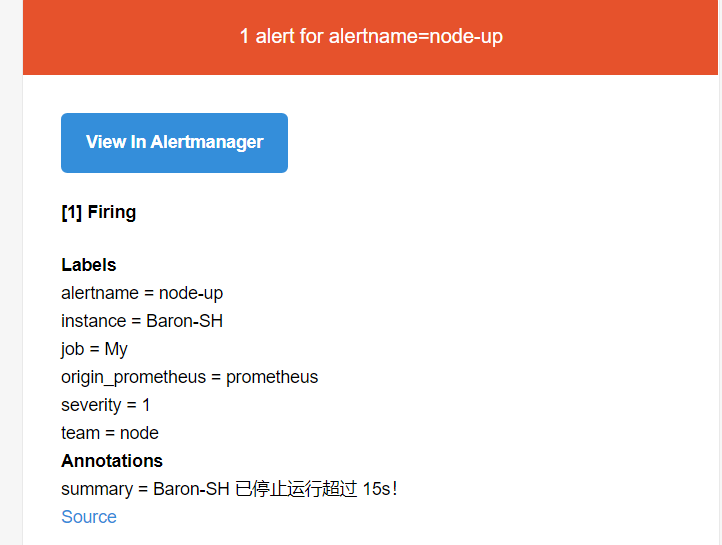
启动 node_exporter 可发现状态恢复如下
其他报警设置 :
服务器状态 CPU 磁盘 内存 等 host.yml 参考Hosts.rules
groups:
- name: Linux
rules:
- alert: "-内存报警"
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 90
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 内存资源利用率大于 90%"
value: "当前内存占用率{{ $value }}%"
- alert: "-CPU报警"
expr: 100 * (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) > 70
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} CPU报警资源利用率大于 70%"
value: "当前CPU占用率{{ $value }}%"
- alert: "-磁盘报警"
expr: 100 * (node_filesystem_size_bytes{fstype=~"xfs|ext4"} - node_filesystem_avail_bytes) / node_filesystem_size_bytes > 90
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘报警资源利用率大于 90%,请及时扩容!"
value: "当前磁盘占用率{{ $value }}%"
- alert: "-磁盘读取报警"
expr: sum by (instance) (irate(node_disk_read_bytes_total{device=~"dm-*|sda|"}[2m])) > 1024 * 1024 * 100
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘读取大于 100MB/s"
value: "当前磁盘读取{{ $value }}MB/s"
- alert: "-磁盘写入报警"
expr: sum by (instance) (irate(node_disk_written_bytes_total{device=~"dm-*|sda|"}[2m])) > 1024 * 1024 * 100
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 磁盘写入大于 100MB/s"
value: "当前磁盘写入{{ $value }}MB/s"
- alert: "-下载网络流量报警"
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[1m])) by (instance)) / 60 / 1024 / 2) > 200
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 最近1分钟使用下载流量每秒超过200Mb/s"
value: "最近1分钟使用下载流量每秒{{ $value }}Mb/s"
- alert: "上传网络流量报警"
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[1m])) by (instance)) / 60 / 1024 / 2) > 200
for: 60s
labels:
severity: warning
annotations:
description: "{{ $labels.instance }} 最近1分钟使用上传流量每秒超过 200Mb/s"
value: "最近1分钟使用上传流量每秒{{ $value }}Mb/s"
#- name: Windows
# rules:
# - alert: "-内存报警"
# expr: 100 - ((windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes) * 100) > 60
# for: 60s
# labels:
# severity: warning
# annotations:
# description: "{{ $labels.instance }} 内存资源利用率大于 60%"
# value: "当前内存占用率{{ $value }}%"
#
# - alert: "-CPU报警"
# expr: 100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 60
# for: 60s
# labels:
# severity: warning
# annotations:
# description: "{{ $labels.instance }} CPU报警资源利用率大于 60%"
# value: "当前CPU占用率{{ $value }}%"
#
# - alert: "-磁盘报警"
# expr: 100.0 - 100 * ((windows_logical_disk_free_bytes / 1024 / 1024 ) / (windows_logical_disk_size_bytes / 1024 / 1024)) > 85
# for: 60s
# labels:
# severity: warning
# annotations:
# description: "{{ $labels.instance }} 磁盘报警资源利用率大于 85%,请及时扩容!"
# value: "当前磁盘占用率{{ $value }}%"
https://blog.csdn.net/wangshui898/article/details/120321640?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120321640-blog-117441154.pc_relevant_multi_platform_whitelistv4eslandingctr2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120321640-blog-117441154.pc_relevant_multi_platform_whitelistv4eslandingctr2&utm_relevant_index=1
没有评论